
東京大学 生産技術研究所の研究者が、自身の研究について紹介します。
揺らぐ
人は、言語を用いて意思の疎通を行いますが、言葉の意味は、誰が、いつ、どこで、誰に対して用いるかによって、揺らぎます。吉永 直樹 准教授は、コンピュータを用いて、人が用いる生きた言葉を正しく理解し、人に伝わる言葉を生み出せるよう、適応的な自然言語処理の研究に取り組んでいます。
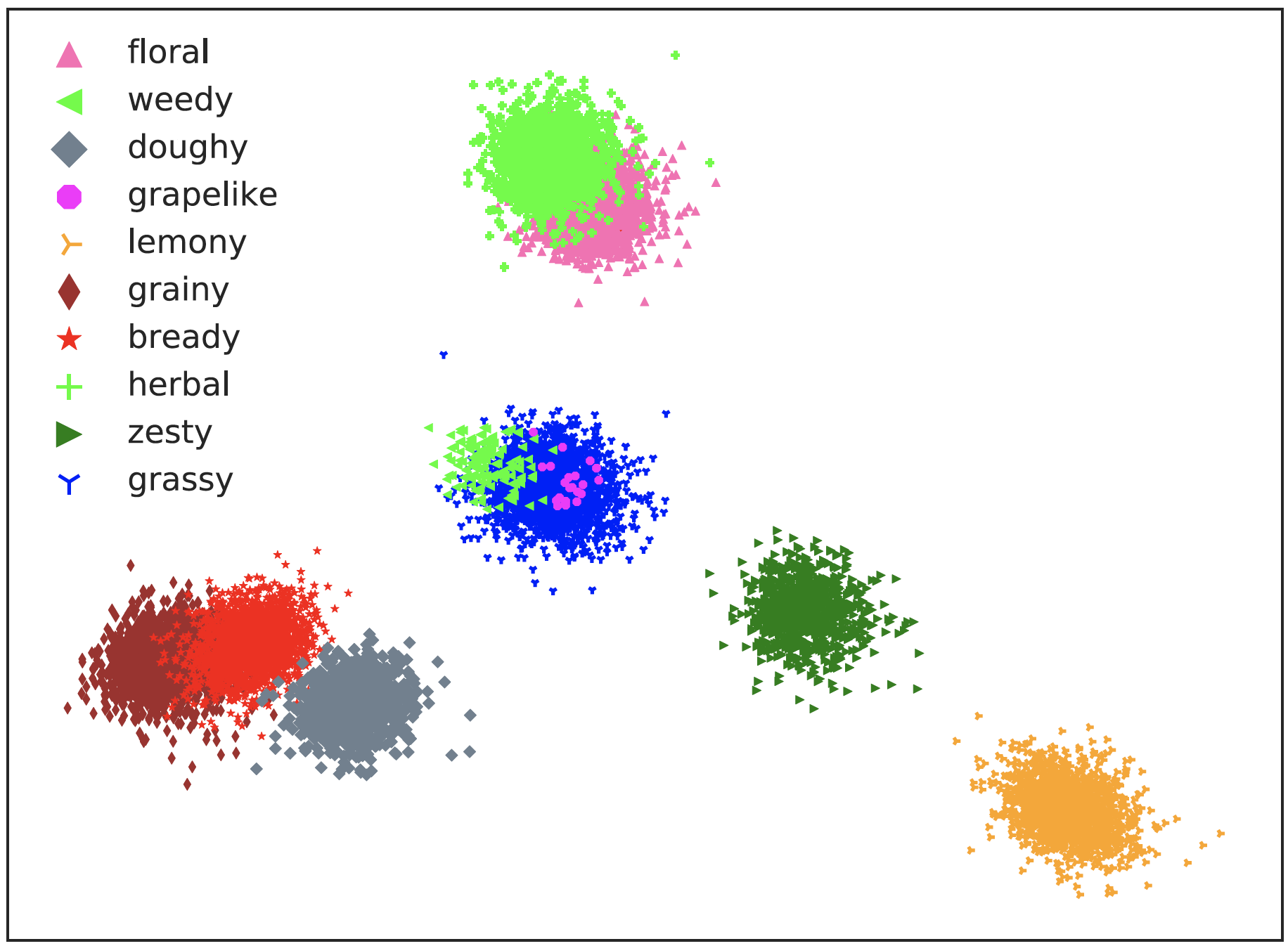
クラフトビールのレビューにおいて個人が単語に込めた意味の揺らぎ(Oba et al. Personal Semantic Variations in Word Meanings: Induction, Application, and Analysis. Journal of Natural Language Processing, 27(2). 2000)
この分布図は、学生たち(主著: 大葉 大輔、2023年博士卒)と進めた研究において、クラフトビールのレビューで味覚を表現するのに用いた単語の意味を、その単語を用いた人ごとにベクトル表現として学習して2次元上の点として可視化したものです。色は単語、各点は人が単語に込めた意味を表現しています。どの単語も、人ごとに意味の揺らぎがありますが、hearbal (+) やweedy(◀︎)のように意味の揺らぎの大きさは単語ごとに差があり、weedyの右上の点のように同じ単語でも大きく外れた意味で用いる人がいることが分かります。また、bready(★)やgrainy(◆)のように、違う単語でも人により同じような意味で使っているものもあり、私たちが用いることばの意味が、いかに曖昧なものであるかが読み取れます。
現在、自然言語処理で盛んに研究され、ChatGPTのような対話型AIを実現する大規模言語モデルは、多様な人が書いた膨大なテキストを束ねて、言語の最大公約数的な振る舞いを捉えるように学習されたものです。大雑把に言うと、大規模言語モデルは、ことばの意味の平均値(上のプロットで言うと、同じ色で表現された単語の意味の中心)を捉えるように学習したもの、と言えるかもしれません。そのため、大規模言語モデルは、誰が使ってもそれなりに満足する結果は得られる一方、誰にとっても最適な技術ではなくなってしまいます。実際、大規模言語モデルから自分の望む応答を得るには、細かく指示を出さないといけないことも多いと思います。
私たちの研究室では、コンピュータを用いて言語を扱う技術を、かな漢字変換や予測入力のように、個人が用いる言葉の特徴に合わせて適応させることを目指しています。具体的に、個人の言語能力を模倣し、自律的に進化する、言語の数理的なモデルの研究を行っています。逆に、このような個人の言語能力を模倣するようなモデルを実現することができれば、そのモデルの中身を上のプロットのような形で分析することで、私たち自身がどのように言葉を(さらには世界を)認識しているか、理解することに繋がります。第二言語を学ぶ途中でネイティブとの言語感覚のずれを認識することができたり、物事に対して潜在的に持っているバイアスを理解することもできるでしょう。また、人と人が会話する際に、お互いを模倣する言語モデルを用いれば、言葉に込めた意味の齟齬を解消するよう、自分の言葉を相手の言葉に翻訳することもできるかもしれません。
Oba et al. Personal Semantic Variations in Word Meanings: Induction, Application, and Analysis. Journal of Natural Language Processing, 27(2). 2000
DOI: 10.5715/jnlp.27.467

記事執筆:吉永 直樹 准教授
みんなのコメント
その未来に期待
その理由は?
まっぴー
自分が使う言語以外の本をもっとネイティブとの言語感覚に近い形で翻訳したり、読んだりできるようになりそう!
投票&コメントで参加
この記事が描く「もしかする未来」をどのように感じましたか?あなたの期待度を投票してください!
もっと詳しい研究内容を知りたい方、疑問や質問がある方は、研究室のウェブサイトをご覧ください。
この記事をシェア